L'Institut national de la recherche agronomique (INRA), or the French National Institute for Agricultural Research, updated their Dataverse-based repository in late January 2019. With the update, the repository, called Portail Data Inra, is able to ingest more types of tabular files, better preserving and presenting tabular data. And the repository sends more metadata to DataCite in order to improve data discovery.
INRA also updated their online tool that researchers can use to generate data papers for datasets deposited into Portail Data Inra. Researchers can enter the DOI (a persistent ID) of any of those datasets, and the tool now generates data papers that comply with formatting requirements from the Data in Brief journal.
The team behind the repository wrote about these and other updates in a post on their website.
In a recent email exchange, Esther Dzalé Yeumo, INRA's head of the Unit of the Department of Scientific Information, shared how Europe’s top agricultural research institute chose and set up Dataverse and how the repository, which hosts over 77,000 datasets, helps improve the organization’s culture of data sharing.

Why did INRA need a data repository? How did the team choose one?
(Esther) We needed software to build both an institutional data repository and a data registry. We are a multi-disciplinary research organization in the domain of agriculture and we already have many data thematic databases. We summarized our requirements and compared them to many data repository tools, which included Dataverse, Islandora, Hydra, and DSpace.
The initial project team included one IT specialist and one librarian. They interacted with a group of about 10 representatives of the different research communities of our institution. This initial phase took about six months.
Why did you choose Dataverse?
Besides our list of requirements, we had limited resources and needed to quickly demonstrate the value of the repository. Dataverse seemed to be the best compromise for us.
We chose it for many reasons: first, the concept of dataverses (containers for datasets and other dataverses, which can be setup for an individual or a group and which can be customized and administered independently) corresponds to our organization and facilitates the adoption of the repository by the researchers. Indeed, we wanted to give the opportunity to different research communities of our institution to define which metadata they want to use to describe their data, define their own data publication workflows, and take ownership of the administration of their data collections.
The second important point is the flexibility in the metadata and facet management/configuration in Dataverse.
Last but not least, the ease of use and the costs were key.
Did INRA's research communities move datasets into the repository?
Yes. We left it up to each group to move their datasets into the repository. Some groups moved their data manually, and there were some batch migrations. Some groups kept the data in the original places and created datasets in Portail Data Inra with links towards those files, like this dataset.
What was the process like for installing Dataverse?
Our team has four developers, three librarians, and a project manager. We first installed Dataverse in a simple virtual machine to test both the installation and configuration process, as well as the functionalities. Then, when we confirmed the choice of Dataverse, we deployed it in two environments with a more complex architecture: a pre-production and a production environment. We also installed related tools such as TwoRavens and Data Explorer.
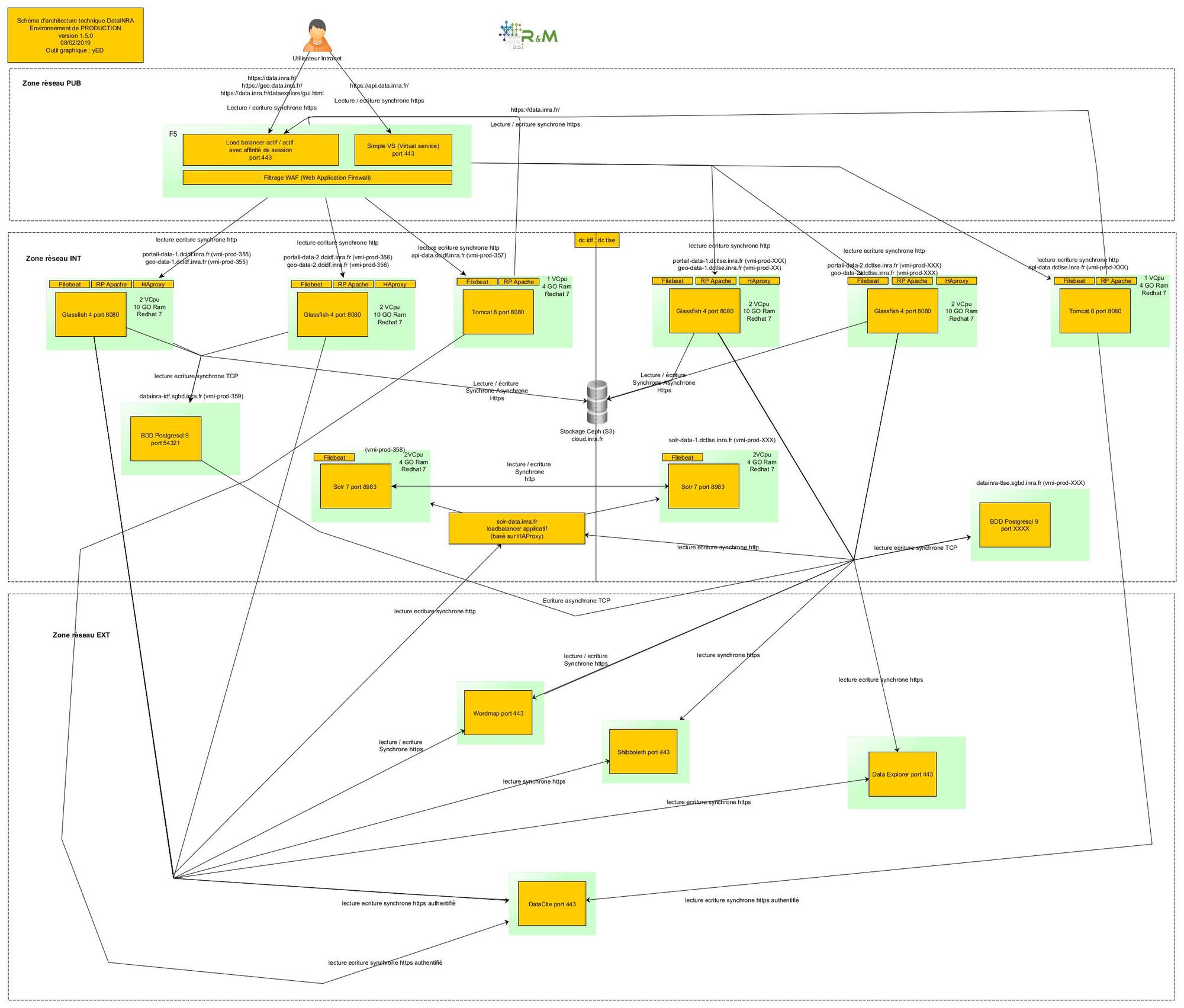
Did you customize anything about the software, or do you plan to?
We added some metadata fields to better support how the scientists need to describe their data.
We also developed an application that takes a list of DOIs and retrieves the related metadata in Dataverse in order to generate a template of a data paper. This is not really a customization of the software but I think it’s worth mentioning.
Examples of things we would like to add are:
- The ability to configure a list of licenses that are compliant with our legal constraints and the possibility for the depositor to choose one of them. Currently, the only predefined option is CC0, which our researchers can’t use.
- The ability for users to comment on datasets.
- More exploratory tools for data types other than tabular and geographical data types, like images and text.
What kind of data are being shared on Portail Data Inra?
Data related to food, nutrition, agriculture, and the environment. It includes experimental, simulation and observation data, omics data, surveys, and text data.
The bulk of the published datasets are in the GnpIS Dataverse. Each of those datasets references a plant genetic resource described in our GnpIS database. A big part of why we did this was to follow the recommendations of the United Nations Food and Alimentation Organization, which recommends the use of permanent unique identifiers for plant genetic resources.
Can anyone upload data?
The institute gives accounts to INRA staff and partners working with INRA on specific projects in order to share data produced by or in collaboration with INRA.
Who is able to download and view the data?
There’s a mix: data that depositors allow anyone to view or download and restricted data.
You mentioned that INRA's research groups and partners are responsible for moving data into the repository. How would you describe INRA’s data sharing culture?
INRA launched a data management and sharing policy in 2013. As a multi-disciplinary institution, we observe different levels of adoption of open data. Some communities like those producing omics data are familiar with the culture of data sharing. Others are newer to it and more reluctant to share their data. Among others, the main obstacles for sharing data are:
- Lack of time and skills to prepare the data before sharing it
- Fear of misuse of the data
- Loss of competitive advantage
The researchers are very concerned about the reuse of the data they can release. So we are working hard to promote the FAIR principles as they offer a better guarantee of good reuse of the shared data.
How is the team promoting Portail Data Inra?
We are promoting the data repository through several channels: online presentations, videos, mailing, and training. We also have an institutional website dedicated to data management and sharing in which we provide useful information and links.
What other services does your group provide?
We provide a DOI minting service, training, consultancy and data preparation.
Last question: Who should people contact to get more information about Portail Data Inra and your group's data management services?
For information about the data repository, people can email datainra@inra.fr. For our data management services in general, use digitalist@inra.fr.